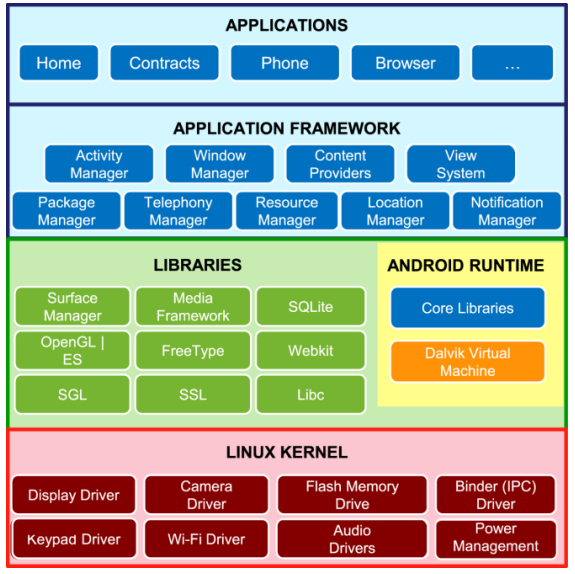
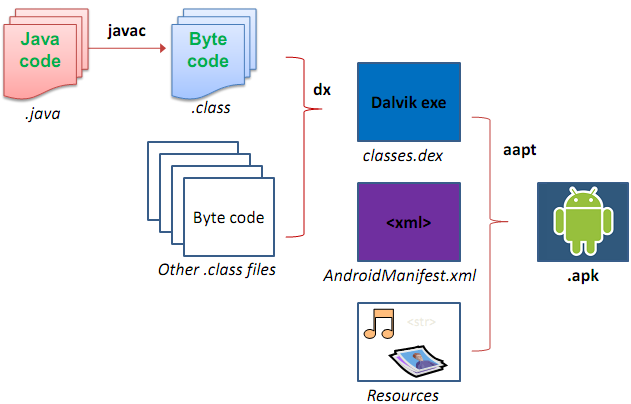
Android 为开发者提供的SDK(Software Development Kit,软件开发包)提供了一系列API,通过调用这些API 即可写出各具形态的app 了,所以我们应该对SDK 有一定的了解。
SDK 中Java 类以树层次结构打包,最上层的是android package,它主要包含了app 的资源类和对安卓系统的权限。如:Manifest | Manifest.permission | R | R.anim | R.array | R.attr | R.color | R.dimen | R.drawable | R.id | R.layout | R.string | R.style | R.xml 等。
android.app 中包含了android已封装好的一些高级类,如: Activity | Service | Fragment 。
Activity 类表示人机交互的一个界面。
Service 类表示一个后台长时间运行的组件,无UI,比如处理网络通信,音乐播放,或者是与一个content provider 交互。
Fragment 类在平板等大屏显示时表示activity 行为的一部分,并且关联相应的UI(可以看做是一部分UI,类似于activity)。
adroid.app 中还包含了其他类和接口:Dialog | ActionBar | Notification 等。
提供基础的操作系统级别的服务:services, message passing,IPC(Inter-Process Communication)。
BatteryManager 电池状态信息。
Bundle 一个从字符值到各种可打包类型的映射。
包含了可以访问android 提供content providers 的类。
包含app 外观设计的一些资源类: R | R.anim | R.attr | R.bool | R.color | R.dimen | R.drawable | R.id | R.integer | R.layout | R.string | R.style | R.styleable 等。
提供了app 布局的一些小部件,如Bar 等。 AppBarLayout | NavigationView 等。
关于文字的类。有关接口和类: Editable | GetChars | Annotation | AutoText | Html | Layout
人如其名,包含一些小工具类,如时间、base64编码、字符串和数字处理方法等。
安卓app 上常用的一些UI 组件类。接口:Menu | ContextMenu | MenuItem 类:Display | Gravity | LayoutInflater (在对应的View 对象中实例化某个XML布局) | MenuInflater | View(UI最基本的组件)
包含屏幕上使用的UI 组件,你也可以自己设计一些组件(实现View 的子类)。类: Button | CheckBox | CheckedTextView | EditText | GridView | ImageButton | ImageView | LinearLayout | ListView | MediaController | ProgressBar | RadioButton | RadioGroup | RelativeLayout | Scroller | TableLayout | Toast 等。
包含了在设备上访问和写入数据的类,主要包括:1.内容分享 (android.content 中的 ContentProvider 、 ContentResolver 、Intent 和 IntentFilter);2. 包管理(访问一个安卓包.apk的信息) 3. 资源管理(获取应用app 相关的资源数据,如strings,drawables,media等)。
包含用于处理从content provider 返回来的数据。如果需要管理一个私有的数据库,请使用 android.database.sqlite 类。
管理Sqlite 的类。接口和类:SQLiteCursorDriver | SQLiteClosable | SQLiteCursor | SQLiteDatabase | SQLiteQuery | SQLiteStatement 等。
提供可以在屏幕上直接画图的低级工具,如画布、滤镜、点和矩形。
提供管理可视化元素(图、灰度等)的类,这些类经常被widgets 作为背景图片或者指示器。
管理音频和视频的类。AsyncPlayer | AudioManager | MediaPlayer | Ringtone
java.net.* 之上的网络访问类。
使用OpenGL 画图。