原文地址:https://www.altera.com/en_US/pdfs/literature/wp/wp-01179-ecc-embedded.pdf
原文名称:Error Correction Code in SoC FPGA-Based Memory Systems
备注:本文是Altera 和Micron 科技的共同编写的技术白皮书。
本文分析了1. 软错误的潜在原因和影响;2. Altera 和Micron 提出的一种错误检测和纠错方法,能够使得嵌入式系统能够容忍这类软差错。
引言
不断进步的半导体工艺技术使得嵌入式系统集成度、功能和性能都在增加。然而,性能的增长也带了巨大的开销,高性能系统的一个负面影响就是必须花费更多精力去处理软差错。随着集成电路供应电压的下降,使得它更容易受到电磁和颗粒辐射的影响。随着嵌入式系统内存大小增大到百兆量级,自然界alpha 粒子导致的软差错可能会超出可接受的限度。另外,现代接口速度超过Gb 每秒,大量的噪声和抖动会造成数据在传输线上写入/读出外部内存时发生错误。
内存比特错误来源
1. 比特单元软错误
通常,被写入数据的比特单位都以电荷值表示其编程值。当向某比特单位写入新值时,将重新编程和强制电荷值变为新值。一般来说,只要基本要求满足,如供电正常,对于动态内存刷新方法有效,内存比特单元内的编程值总是确定的。
但是,存储的电荷值会受到射入内存系统外部电荷的负面影响。宇宙粒子和大气中的原子碰撞产生能量射线可能会影响到存储的电荷值。要使得内存比特单元值跳变,必须向其注入足够多的电荷才能使得其表示为一个错误的逻辑值。
宇宙射线中百分之十以上由高能alpha 粒子组成,它们能够穿透几米厚的混凝土。芯片封装材料在衰减过程中会释放出低能alpha 粒子,因为能量小,其传播的距离和影响也小。类似地,gamma 射线也是表现为宇宙射线的一种高能粒子,由自然界衰减造成。地球的大气环境对于宇宙射线和粒子是一个天然、有重要意义的屏障,但绝不是天衣无缝的。结果就是,在高海拔,如山顶上、航空系统,大气环境能够提供的保护更少,发生软错误的几率更高。
这类因为外来能量注入无意地修改内存比特单位中数值叫做单粒子翻转(single event upset, SEU)。这类错误是软错误,这类错误的原因不是因为设备的缺陷造成的,而是由于设备所在环境的外部干扰造成。一旦正确的数据因此发生重写,几乎不可能再次经历SEU而翻转回来。这类事件的可能性极小,并且随着内存容量增加而增大。
2. 硬件错误
硬件错误被被归类为功能性错误。这类错误往往是可重复的、持续性的。一个包含了内存设备的系统被制造出后,应该是没有故障的,但随着系统寿命的增加,这种状况可能发生改变。各种因素,如频繁的温度变化、电压、高湿度和物理压力,都可能会引起系统中部件的失效。这类错误可能会表现为一个内存单元或一个印制线缺陷导致的比特卡顿(bit stuck,某位比特单位读出、传输结果总是1或0)。
3. 传输错误
传输错误发生在内存比特单位和功能性单元之间的读写数据路径上。这类错误一般是因为系统中短暂地超过系统设计余量的抖动和噪声造成,因此它们与设计余量、使用系统部件质量和系统对所在环境的电能敏感度有关。
物理连接到外部内存的电感、电容数量和导线长度比片上系统(System-on-Chip,SoC)或者内存系统中的内部布线要高出几个数量级。不过,部件内部还是可能发生传输错误。Alpha 粒子和gamma 射线能够影响感应放大器和内存比特线,导致获取到错误的数据值。
图一:传输错误
4. 数据错误的影响
内存数据的损坏对于嵌入式系统的运行通常是致命的。在基于处理器的系统中,内存错误会导致指令或数据流中的值不正确。现代处理器会检测到非法指令,通常会迫使系统重新启动。数据流中的错误可能会导致程序流出轨,往往会导致非法访问受保护的内存。这些事件在桌面系统中表现为“死亡蓝屏”或“core dump”。
尽管在嵌入式系统中崩溃是令人讨厌的,但是想要有个替代方法也不是那么简单。没有立即检测出的错误可能会长时间滞留在系统中。由于错误的数据用于计算新数据,未检测到的内存错误可能会倍增。而一旦检测到错误的数据,错误的起点以及造成的后续影响将很难确定。
嵌入式系统通常运行时间较长,并不像在台式计算机那样频繁地重新启动。这给嵌入式系统带来了额外的缺点:错误将随着时间推移而累积。数据错误和系统崩溃的负面影响很多:异常行为的系统会令用户烦恼,让顾客感到不快;维护成本可能会增加,因为客户的投诉会触发对不可重现错误来源进行昂贵的调查;突然的系统故障可能会造成重型机器周围的不安全环境,而且安全系统中的错误可能会导致意外的系统访问后门。
5. 嵌入式系统中错误的可能性
硬错误率和传输错误率是许多变量的函数。在较大系统中对于这类错误的研究比较成熟,但研究结果并不能直接将应用于其他系统。另一方面,已有很多研究发布了软错误率(Soft Error Rate,SER)结果。举一个实际例子,一个有1GB 内存的嵌入式系统的平均故障间隔时间的范围在一年几次和几年一次。
MTBF 还应该考虑到该领域系统数量。系统供应商则应该考虑一个给定时间段内可能发生失效设备的总数。假设10000 台设备的MTBF 是十年,那么意味着平均每年都将有1000 台设备遭受一次单比特错误。
这种错误率的可接受性取决于应用领域。在高海拔使用的应用开发人员将关注由于宇宙射线造成的较高的SER。军事,汽车,高性能计算,通信和工业客户将更关注错误率导致的安全性和可靠性的下降。在消费领域,一年的MTBF 则有时可以被接受。然而在许多情况下,错误率造成增加维护成本和不满意的客户数量是推动解决方案的关键因素。
提高容错能力
1. 传输错误
Altera®SoC FPGA 支持高达533 MHz(1066 Gbps)的DDR3。 DDR3 接口规范以及SoC FPGA 与外部存储器器件中实现的方式保证了错误率可以忽略不计,因为于DDR 规范所限定的范围内具有可靠的电路板设计和抖动和噪声控制。
谷歌与多伦多大学合作进行的大规模研究以及斯坦福大学的另一项研究表明,被分析的所有系统中大部分错误仅是由系统的一个设备子集造成。这些错误很可能是由过度的抖动或噪声引起的,或可能与系统及其组件的质量不合格有关。
传输错误发生的概率会随着接口速度的增加而增大,比如DDR4 或更高。随着功耗降低和接口速度提高,电源层面的电压和信号电平也随之缩小,抖动和噪声越来越难以控制。
随着更高的接口速度而增加,例如为DDR4及更高版本所定义。随着功耗降低和接口速度提高,电源层面的电压和信号电平也随之缩小,抖动和噪声越来越难以控制。 JEDEC 指出,对于DDR4 和GDDR5 的下一代存储器规范,抖动和噪声的影响已经促使该规范允许在一定的误码率和简化设计,特性和鉴定之间权衡。任何需要容忍的误码率都将用一种有效的方法来纠正发生的错误。
2. 软错误
因为软错误是不可避免的,所以已研发出了一些方法能够使得系统对这些错误具有抵抗力。也就是说,当一个错误发生时,它能够被检测、校正并传输校正后的值,因此系统可不中断地运行。这个壮举是通过向内存数据段中添加字节实现的,那么加宽的数据段携带了足够的信息来检测和校正错误。数据字段中增加的比特越多,能够被校正的错误也就越多。这使得纠错成为成本和期望可靠性的函数。能够修正一个错误和检验出两个错误的纠错方法即具有成本效益,又被证明在嵌入式系统中提供了出色的错误恢复能力。这种在工业界被广泛应用的技术叫做纠错码(Error Correction Code,ECC)。
3. ECC 的基本实现
通过增加内存容量,并在进出额外的外部内存的通道上增加有限的组合逻辑可以实现ECC。逻辑部分用于ECC 编码,采用非常成熟的多项式汉明(Hamming)算法。一个ECC 比特产生器可以为正在存储的数据生成ECC 数据,并将ECC 数据和普通数据一起存储。ECC 检测和校正逻辑函数被插入在内存的输出端,当从内存读取数据,这个函数将检验ECC 数据和普通数据的组合。如果没有检测到错误,则直接传输普通数据而不做任何改变。如果检测到一个错误,它将纠正普通数据内的错误比特位,并返回纠正后的数据,可选择性地抛出一个异常标志。当检测到两个错误时,则抛出一个异常标识,让系统因地制宜地去响应这个事件。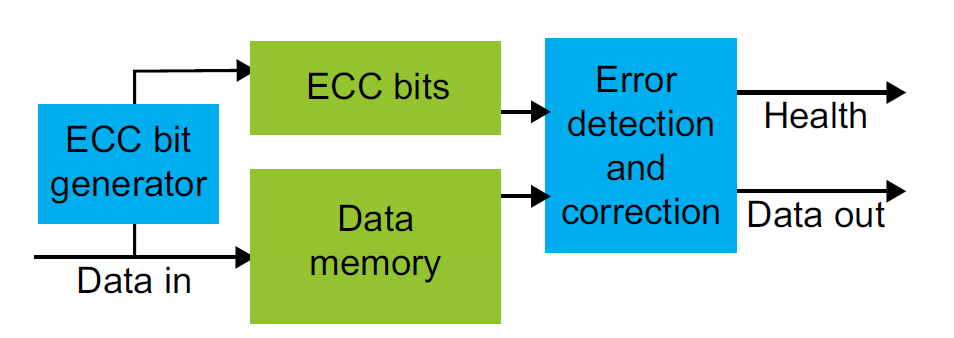
图2:ECC 内存容量更大且增加额外的逻辑部件
4. ECC 优势
能够纠单错和检测出双错具有很多好处。虽然ECC 是由大内存的SER 问题推动的,但它也增加了抵御其他类型错误的能力。一个硬件单错,比如内存中的比特卡顿或印刷电路板上的不稳定连接,都能够被ECC 完全掩盖,同样单比特传输错误也同样能被解决。核心是ECC 可以校正一个数据段中的错误比特。也就是说,ECC 可以正确地处理系统中的多个错误,只要任意一个数据段中发生不超过一个比特的错误。
另一个好处ECC 逻辑能够指出系统的健康状态。当ECC 逻辑纠正了一个数据段中的单错,它还可以向处理器发送一个故障状态信号,以利于处理器采去与系统所需的可靠性相关的措施。这一手段将系统降级转化为可调度的维护任务,而不是响应意外的、致命的系统错误状况。基于启发式概率,附表分析了有ECC 和没有ECC 的系统的估计软错误模型,表明ECC 有效地增加了MBTF,使其从短于系统寿命增加到比宇宙寿命更长。
表1:ECC 使得容单错能力大大提高
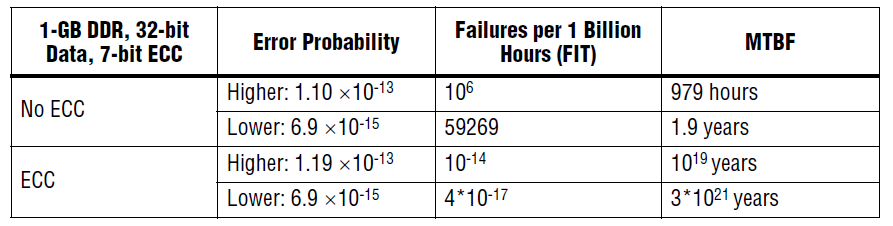
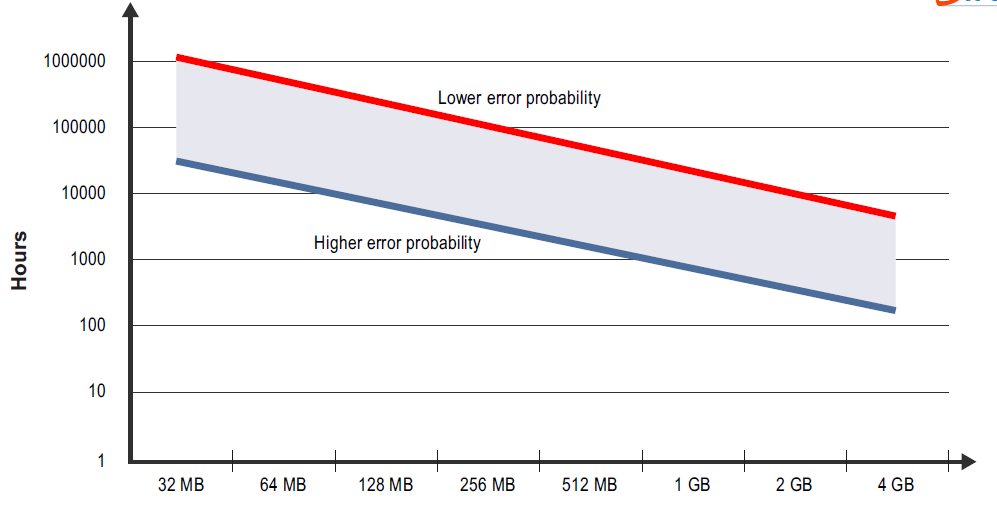
图3:外部DDR 内存没有错误校正的软错误MTBF
Altera 和Micron ECC 解决方案
1. 外部DRAM 的ECC
为Altera SoC FPGA 的外部内存添加ECC 功能只需要增加内存数据带宽。生成ECC 比特、错误检测和校正的功能都已经内置到SoC FPGA 的内存控制器中,这样的话,虽然带宽变大,但内存具备了ECC 功能。此外,在SoC FPGA 和外部内存之间的数据通道上已经布置了ECC,因此在数据通道上也可以恢复某些传输错误。
具有16-bit 或32-bit 宽的数据通道的外部内存系统在SoC FPGA 和外存之间分别需要存储额外的6 或7 个ECC 存储位。 对于这两种情况,Altera 架构简化为定义一个额外的1 字节的ECC 内存存储位。
2. ECC DRAM 的典型架构
一个由SoC FPGA 和外部存储器组成的现代嵌入式系统可能需要包含1 GB 的DRAM。 为了实现这种系统的高性价比的32 位宽内存接口,一个典型的DRAM 可以包括并行配置的一个8位宽器件和两个16位宽器件的组合。
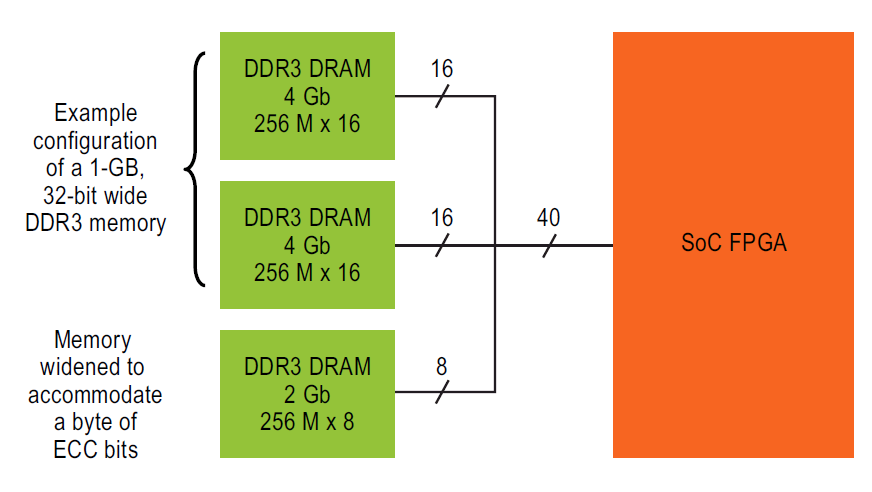
图4:典型的外部DDR 内存架构
3. ECC NAND 闪存
外部的NAND 闪存可以连接到SoC FPGA 器件,既可以作为一个存储引导配置的内存,也可以作为存储应用程序的文件系统。NAND 闪存对软错误非常敏感,并且经常需要ECC 保护。不同于外部DDR 内存将数据段带宽变宽,NAND 闪存提供额外的存储缓冲区来保存ECC 数据。ECC 所编码的数据块也更大,如512 或1024 字节,那么SoC FPGA 设备则能够校正高达24 比特的错误。尽管实现方式被调整为更适应NAND 闪存的一般错误模式,但恢复方法还是类似于常规的SRAM 和DRAM。
4. Altera SoC FPGA 的错误恢复
ECC功能内置于SoC FPGA器件中,用于大量片上内存实例。L2 缓存,临时RAM,FPGA 结构内部的内存和外围上作为数据缓存的内存都带宽加宽并装备上了ECC 产生器和逻辑校正器件。由于这些是内置的,使用ECC 功能不需要额外的成本。 同样地,外部内存和NAND 闪存的ECC 也内置在SoC FPGA 中。数据和指令缓存在物理大小上相对较小,因此不容易发生软错误。因为它们需要高速运行,也为了读取L1 缓存时避免额外的延迟,系统使用更简单的奇偶校验方法。
FPGA 架构内的配置数据不是以增宽的数据段来组织的,因此也没有用ECC 校验。FPGA 架构内部有一个内置的硬件引擎,允许循环地检查配置数据的正确性,当检测到一个错误时会抛出一个异常标志。这种错误校正方法称作“擦洗(scrubbing)”,也是这类设备的一种工业标准方法。Altera SoC FPGA 具有支持系统级的错误恢复所需要的逻辑器件,并集成到设备中。通过仅扩展外部DDR 内存,可以获得对软错误和传输错误具有恢复能力的通用综合系统级方法。
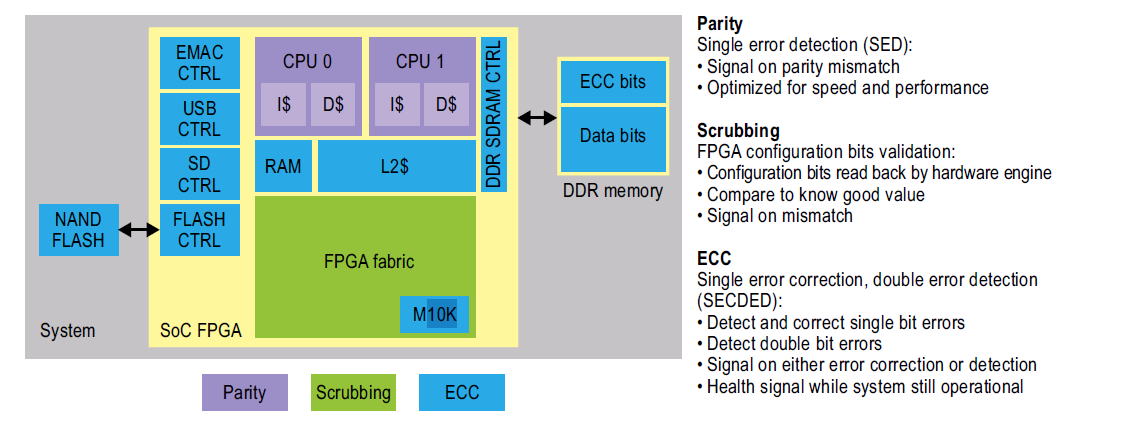
图5:SoC FPGA 系统级的容错能力
总结
嵌入式系统中的内存可能受到宇宙射线的注入而导致比特位翻转,而过度的噪声和抖动也会导致传输错误,从而使得传输的数据不正确。虽然这种错误可能性很小,但随着内存容量、接口频率和带宽的增大,这类事件的可能性越来越成为挑战。系统级错误恢复能力日益成为高性能嵌入系统设计的考虑因素。Altera SoC FPGA 设备通过擦除(scrubbing)、奇偶校验和ECC 技术实现高容错能力。它能够很方便地为外部内存增加ECC 功能,特别是兼容了高性能系统中32-bit 位宽的外部DRAM 内存。增加ECC 实际上消除了内存对这些错误的敏感性,为系统级别的容错做出了重要贡献。
扩展阅读
“A Second Look at Jitter: Calculating Bit Error Rates,” Justin Redd, Maxim Integrated Products:
www.eetimes.com/electronics-news/4164171/A-second-look-at-jitter-Calculating-bit-error-rates
■ “Understanding the New Bit Error Rate DRAM Timing Specifications,” Perry Kelly, Agilent Technologies:
www.jedec.org/sites/default/files/Understanding%20BER%20based%20timing%20specifications%20Agilent%202011_1101.pdf
■ “DRAM Errors in the Wild: A Large-Scale Field Study,” Bianca Schroeder, University of Toronto, Eduardo Pinheiro and Wolf-Dietrich Weber, Google Inc.:
www.cs.toronto.edu/~bianca/papers/sigmetrics09.pdf
■ “Hard Data on Soft Errors: A Large-Scale Assessment of Real-World Error Rates in GPGPU,” Imran S. Haque, Vijay S. Pande, Stanford University:
http://cs.stanford.edu/people/ihaque/papers/gpuser.pdf
■ White Paper: Enhancing Robust SEU Mitigation with 28-nm FPGAs , Altera Corporation:
www.altera.com/literature/wp/wp-01135-stxv-seu-mitigation.pdf
■ On the Need to Use Error-correcting Memory,” Berke Durak:
http://lambda-diode.com/opinion/ecc-memory