一、背景与挑战
数据的爆炸式增长使得存储系统的规模不断增加,存储设备的可靠性却一直没有得到显著提高(SSD 从SLC 到MLC 和TLC 可靠性不断下降,磁盘随着单位面积写入数据更多导致可靠性无法提升),从而给数据的持久化存储带来巨大挑战。另外随着存储系统规模的增大,存储系统中的冷数据的增加将远超过热数据的增加,如何安全保存冷数据,在需要的时候能够获取冷数据也成为存储系统中的重要挑战。下面是近年全球估计的数据量增长情况(GB,TB,PB,EB,ZB,YB…)。
2007 281 EB
2010 1.2 ZB
2011 1.8 ZB
2020 35 ZB
二、副本 V.S. 纠删码
副本策略和编码策略是保证数据冗余度的两个重要方法。当原始数据发生部分丢失时,副本策略和编码策略都可以保证数据仍旧可以正确获取。副本策略将原始数据拷贝一份或多份进行存储,编码策略则将原始数据分块并编码生成冗余数据块,保证丢失一定量内的数据块,原始数据仍旧可以获取。

图1. 副本策略

图2. 编码策略
两种策略性能比较如下:
| 存储效率 | 计算开销 | 修复效率 | |
| 副本策略 | 低 | 无 | 高 |
| 编码策略 | 高 | 有 | 低 |
虽然编码策略比副本策略存在计算开销和修复效率低(后面将介绍)的缺点,但能够极大的减少存储开销的优势还是为编码策略赢得了巨大的空间。实际中,存在着副本策略和编码策略的存储系统,比如在分布存储系统(HDFS, GFS, TFS)中热数据往往通过副本策略保存,冷数据则通过编码后保存,节省存储空间。在ECC内存和SSD的page 中也使用了ECC 编码策略保证数据冗余。
下面通过一个方程组的例子啰嗦下这两种策略,如果将原始数据比作如下一个方程组S(x 和 y对应着原始数据的两部分):
x = 1
y = 2
副本策略复制相同一个方程组S’ ,当任何一个等式失效时,仍然得到相同的方程组:
x = 1 x = 1
y = 2 y = 2
编码策略则是通过线性组合这两个方程组得到一个新的方程
x = 1
y = 2
2(x) + (y) = 4
这样就保证了三个方程中任意两个都可以线性组合得到x 和y 的值。
三、相关参数
以磁盘做为单位存储设备的存储系统中,一般会有以下参数说明:
-
n : 存储系统中磁盘总数
-
k : 原始数据盘个数或恢复数据需要的磁盘
-
m : 校验盘个数(m = n-k)
编码策略编码k 个数据盘,得到m 个校验盘,保证丢失若干个磁盘可以恢复出丢失磁盘数据,编码效率R = k/m。磁盘可以推广为数据块或者任意存储节点。
四、 编码(encode)、解码(decode)和修复(repair)
以图3 为例,k(4) 个数据盘编码为m(2) 个校验盘(parity disk)的过程为编码过程,从任意k 个磁盘中恢复原始数据盘的过程为解码,修复过程是从若干个磁盘(一般是k(4) 个)中恢复出一个或若干个磁盘的数据,修复过程在RAID 系统中也叫数据重建。


图3. 编码和解码过程
五、MDS 性质
MDS 性质是纠删码的一个重要性质,它保证n=k+m 个磁盘中任意k 个磁盘都可恢复出k 个数据盘,或可表示为该编码容忍任意m=n-k 个磁盘发生故障,而数据不发生丢失。传统的RS 码、CRS 码都具有MDS 性质,最近提出来的一些编码往往牺牲MDS 性质(Rotated RS,Local Repair Codes等),减少修复开销(之后的文章将详细介绍)。
六、系统码(systematic codes)和非系统码(non-systematic codes)
系统码指的是编码后包含原始数据和校验数据(parity data)的编码方法,系统码编码后只包含校验数据,而没有原始数据。在存储系统中系统性(systematic)是非常重要的,这样保证原始数据在读取的时候不用解码即可得到,所以常见的RAID 码,RS(Reed-Solomon)码,CRS(Cauchy Reed-solomon) 码都是系统码。也有一些编码如随机线性编码(Random Linear Codes,RLC)是非系统码,在存储系统用运用较少。
七、编码矩阵(Generator Matrix,GM)
从信息论和编码的角度来说,纠删码属于分组线性编码。其编码过程可以通过一个编码矩阵GM 和分块数据的乘法(点积)来表示,也就是说编码矩阵GM 定义了数据是如何编码为冗余数据的。以图4、图5 为例,C0 ~ C5 是冗余数据,所有的冗余数据可以表示为GM × D{D0、D1、D2、D3} 的乘法,每一个冗余数据块Ci 是矩阵的对应的一行和数据块的乘积(黄色标示)。编码矩阵中GM 每一个元素则是对应原始数据块的乘法系数。编码矩阵的列数对应着原始数据分块个数(k),行数对应着编码后所有数据块个数(n)。

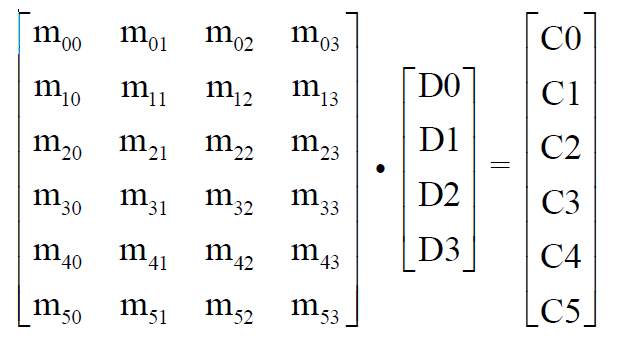{kind=link}

图5. 编码过程的数学表示
如果一个编码是系统码,则编码矩阵的前k 行构成一个k×k 大小的单位矩阵,剩余后n-k = m 行构成m×k 大小的校验矩阵(parity matrix)。单位矩阵和原始数据的乘法得到的还是原始数据,校验矩阵和原始数据的乘法得到校验数据。图6 是系统码RAID 6(k = 4、m = 2)编码示意图,左边是其编码矩阵GM。

图6. RAID 6(k = 4、m = 2)编码示意图
MDS性质在编码矩阵GM 中的表示则是矩阵的任意k 个行向量组成的矩阵都是满秩的。
八、数据块大小和条带(stripe)
数据块大小指的是数据块进行编码计算时,数据分块(原始数据块Di 或校验数据块Cj)的大小,在不同的存储系统中数据块大小不同,在RAID 存储系统中,常见的分块大小是4KB~128KB,在分布式存储系统中数据块较大,一般为64MB大小。条带是纠错编码存储一次性读入或写入数据的大小,在系统码中,一个条带往往包含了k 个原始数据块和m 个校验块,如图7。

图7. 条带(stripe)示意图
七、水平码和垂直码
水平码指校验数据存放于单独的校验磁盘(黄色)的编码方法,每个条带都是水平方式存储于n 个磁盘中,相同条带的数据块位置相同。垂直码的校验数据分布于所有的磁盘中,没有单独的校验盘,每个条带倾斜地将每个数据块分布于磁盘上不同位置上。



图8. 水平码垂直码
常见的纠删码在实际系统中都是按照水平码分布数据,但在理论研究中,科研人员更喜欢垂直码,因为其在理论上具有更好的性质,但在真实的系统中很少看到有实现。