Python 2.* 的程序员肯定遇到过这样那样的字符编码问题:
- 为什么从网站上爬取的html 在本地显示的就不正常?
- 为什么会显示 UnicodeEncodeError: ‘ascii’ codec can’t encode character 这样的错误
- python 中encode(),decode() 方法如何使用?
这样的字符编码问题总会让新手、老手都头痛,有时候即使解决了问题也不能完全知道原理。然后似乎这样的问题似乎在Python 3 中却又解决了?Python 3 又是如何解决字符编码问题?。写在python 2.* 即将要退出历史舞台时候,不知道以后python 程序员还会不会遇到这样的问题。但即使python 不会再有编码问题的困扰,更低级的语言可能还是会遇到,字符编码的原理也不会变化。
一、从编码的历史谈起
将任何一门课程(专业)都要从这个课程所研究的历史讲起。这是因为了解了历史问题,才能够明白课程需要解决的真正问题是什么?知道了这些年解决历史问题的方法,才能够反映出最新解决方法的先进性,也明白了为什么我们(课程)要这么做。
字符是信息的一种体现,字符编码也是信息编码的一个子集。如果考虑到古代的绳结记事、甲骨文和壁画也是信息的一种编码,我们这里所讲的字符编码指的是:自然语言字符(文字)在现代计算机上的映射方法。字符编码的来源是人类自然语言(文字),编码结果是存储在现代计算机上的二进制串。之所以是映射,因为每一个自然语言字符所对应的二进制串是唯一的。
1.1 ASCII 码表
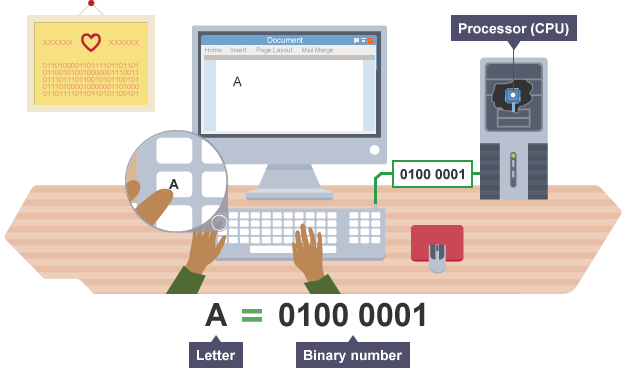
现代计算机起源于英语为母语的美国,所以最初美国工程师在字符编码中首先考虑的是自己母语的使用方便,即26个英文字母(大小写),0-9数字和常用字符的编码。在1963年颁布了ASCII (American Standard Code for Information Interchange)字符编码表,如下所示:

ASCII table
ASCII 表包含字符个数128(2^7)个,因此任何一个字符都可以在一个字节内存储下来,不会出现超过一个字节的字符。计算机解码时按字节解码即可,非常方便。ASCII 表不仅定义了像空格(space)、字母等可见字符,还定义了一些不可见字符。使用下面的代码可以输出0-127 的ASCII 码表。
for ii in xrange(0,128) print chr(ii)+'\t'ASCII码表很好的解决了英语为母语的计算机使用者的信息存储问题,但人类的科技进步的成果也必须全人类共享啊。但如果仅靠一个字节来保存全世界所有语言的字符肯定是不合适的。如果法国人要将自己语言中的 é, è, ê or ë 输入到计算机怎么办呢?更不用说中韩日语以庞大数量汉字为基础了。
1.2 GB2312 中文字符编码
为兼容本地语言,各个国家开始制定了自己语言的编码方法。但为了向下兼容英语,各种编码方法都是在ASCII码上进行了扩展。我国常使用的GB2312 是最常见的中文编码方法,GB2312 于1980 年颁布,所以其标准号是GB2312-1980。GB2312 按两个字节编码一个中文字符,共收集了6763 个汉字和682 个非汉字图形。GB2312 不仅收录了中文,还收录了拉丁字母、希腊字母、日文片假名、平假名字母等。
GB2312 将两个高、低字节(第一个字节为高字节,第二个为低字节)分别称为区字节和位字节,一个区包含94个字,共计94个区。GB2312 规定区字节仅 0xA1-0xF7 (01-87加上0xA0)存储汉字,位字节 0xA1-0xFE 存储汉字。GB2312之所以从A0 开始编码可以避免与ASCII的冲突,比如打开一个GB2312 编码的文件,如果字节值小于128,则这是ASCII字符;如果字节值大于128,则这个字节属于一个汉字。
下面的方法给出了中国字符“您好!”和GB2312 编码后结果:
>>> ("你好").decode('gb2312').encode('gb2312')
'\xc4\xe3\xba\xc3'
>>>这里需要解释下decode() 和encode() 函数了。首先需要明白Python 中有两种字符串类型,一种是str 字符串,一种是unicode 字符串。比如 ‘你好’ ,’news’,’나는 당신을 사랑합니다’ 是str 字符串,而 u’你好’ 则是unicode 字符串。
decode() 是将str 字符串转化为unicode 字符串;
encode() 是将unicode 字符串转化为str 字符串;
以GB2312 为代表的区域性字符编码方法还是存在着通用性的问题。
- 因为不同国家指定了不同的字符编码方法,相同的0/1 字符串在不同的字符编码方法中很可能对应不同的字符。那么打开一个文件,首先得知道它的编码方法才行。
- 为全世界语言字符进行统一的字符编码(或者制定一套各地域字符编码方法的转换规则),两个字节肯定是不够的,那么需要更多字节来存储字符么?
1.3 unicode
unicode 可以看做一个终极的字符编码方法,它给出了地球上常用字符的二进制映射,而且所有的二进制字符串唯一地表示一个字符。当然unicode 也向下兼容ASCII,下面给出了一些字符所对应的二进制、十六进制值。
字符 十六进制 二进制
I 49 01001001
J 4A 01001010
日 65e5 01101001 11100101
ᅱ FFD6 11111111 11010110
♀ 2640 00100110 01000000
♬ 266C 00100110 01101100
unicode包含了人类常用的语言字符、标识等字符编码,目标是统一全球字符编码,它也似乎正在向这终极目标迈进。但也可以看出unicode 只给出了字符和二进制串的对应关系,并没有给出存储形式。而不同字符所占用的存储空间可能不同,比如ASCII 在unicode 中只占用了一个字节即可,而常用汉字在unicode 中需要占用两个字节,还有一些罗马字符可能需要三个或以上字节。如果直接存储的话可能导致无法分割字符串,也无法正确解码出字符,比如计算机读到了“65e5”,这是中文的日字还是两个字符(’65’ 和 ‘e5’在unicode 中对对应的字符)呢?
关于unicode 问题:如果计算机读到一个字节,如何判断这个字节是新的字符的开始,还是一个未读完字符的继续呢?
这个问题在ASCII 码表和GB2312 中是不存在的,因为所有字符都是固定长度。那么unicode 可不可以也使用最大的长度字符的字节数来表示呢?当然可以,比如最大unicode 用四个字节可以保存,那么所有的字符都占用四个字节,但问题就是需要的存储空间变得很大。比如unicode 对应字符的存储如下(这么多0 是不是浪费了很多存储空间呢?):
I 00000049
J 0000004A
日 000065e5
ᅱ 0000FFD6
♀ 00002640
♬ 0000266C一个可以想到的办法就是在一个8 bits 的字节中,第一位用来保存是否是字符的开始(1表示这是一个新字符,0表示这个字符的unicode 还没有结束),后面七位用来保存unicode 的值。这是一种变长编码方法,即每个字符的编码后所占空间是不同的(下面称作首位编码)。
字符 十六进制 二进制 首位编码
I 49 01001001 11001001
J 4A 01001010 11001010
日 65e5 01101001 11100101 10000001 01010011 01100101
ᅱ FFD6 11111111 11010110 10000011 01111111 01010110
♀ 2640 00100110 01000000 11001100 01000000
♬ 266C 00100110 01101100 10010011 00011011每次解码时,将字符每个字节除去第一位(红色标示)的其他位拼接得到的值作为其unicode 值。但这种方法我能想到的存在问题就是效率低,处理器每次只能一个字节一个字节的处理,读取到第一个字节时并不能知道这个字符占多少个字节,而且没有办法知道中间数据是否发生损坏。而我们常见的UTF-8 却可以很好解决这个问题。
1.4 UTF-8
该UTF-8 出场了,简单地说,UTF-8 是unicode 在计算机中的一种实现方式。和我们上节提到的首位编码类似,也是一种变长编码,每个字符占1-4 个字节。UTF-8 将字节分为数值位和标识位,数值位真正保存字符编码数值,标识位表示这个字节是属于哪个字符的、或者该字符占多少个字节。UTF-8 编码方法的:
单字节,首位为标识位0;多字节字符首字节标志位1··10开头,字符占多少字节则有多少1,其他字节标识位10开头;
- 单字节字符: 0xxxxxxx (以0 开头标志位,数值位用x 表示)
- 双字节字符: 110xxxxx 10xxxxxx
- 三字节字符: 1110xxxx 10xxxxxx 10xxxxxx
- 四字节字符: 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
解码时,如果字节首位是0,那么这个字节是个字符;如果字节以i 个1开头,那么这个是一个i 位字符。那么unicode 又是如何填入到UTF-8 的空缺(x)中呢?首先来看看每个多字节UTF-8 编码对应unicode 值的范围:
UTF-8二进制 unicode二进制
0xxxxxxx 00-7F
110xxxxx 10xxxxxx 0080-07FF
1110xxxx 10xxxxxx 10xxxxxx 0800-FFFF
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx 00010000-10FFFunicode 变为UTF-8 编码非常简单,unicode 二进制按照从低到高,填充UTF-8的数值位,除去那些不真正表示数值的标识位(字节开头的0,10,110,1110和11110),顺序也是由低到高。以汉字“你”为例,看看unicode 如何转换成UTF-8 编码。
>>> (u"你").encode('utf-8')
'\xe4\xbd\xa0'
>>> (u"你")
u'\u4f60'“你”字unicode 编码为 ‘4f60’ (二进制 ‘01001111 01100000’)。从“你”的unicode 值范围可以看到需要三个字节,接着从低位字节向高位字节填充得到“你”的UTF-8 编码(高位没有填充完则用0补充)。
字符 unicode十六进制 unicode二进制 UTF-8二进制 UTF-8十六进制
你 4f60 01001111 01100000 11100100 10111101 10100000 e4bd60可以看到将UTF-8 用于标记位(红色)的位去掉,合并可以得到原始的unicode 码。
二、文件和终端编码格式
所有的文本文件在计算机中存储的都是一串有限长度的二进制串,只有使用合理的编码方式才能正确地显示文件,但文件本身又是如何告诉编辑器它是如何编码的呢?
2.1 py 文件的字符编码
实际上如果文件本身不申明,编辑器是不知道一个文件所采用的编码方法的。所以编辑器有一个默认的打开方式,比如记事本(notepad)和notepad++ 都默认用ASCII 打开文件。作为Python 初学者可能会遇到下面的一个问题:
故障1:新建一个test.py 文件,用记事本默认打开,输入下面内容:
import os
print "你" 保存后在终端运行”python test.py” 发现提示错误:
>>python test.py
File "test.py", line 2
SyntaxError: Non-ASCII character '\xc4' in file test.py on line 3, but no encoding
declared; see http://python.org/dev/peps/pep-0263/ for details发现提示存在非ASCII 码字符,这是因为在记事本中中文默认使用GB2312编码,”你”的GB2312 编码是”\xc4\xe3″,于是在执行test.py 文件时,出现了无法识别的字符’\xc4’。如果将文件修改为’UTF-8′ 编码时,则可以看到因为”\xc4\xe3″是不合法的字符串,所以显示为它的二进制内容。
写过Python 程序的都知道,为了避免py 文件内的编码问题,需要在文件首做一个申明:
#_*_encoding:utf-8_*_这样,编辑器在开个你这个文件的时候就会默认按照UTF-8 格式打开。当然,UTF-8 也可以换做其他格式。
2.2 python 与文件的字符编码
除了py 文件本身要保存为UTF-8 格式,以避免出现py 文件出现的非ASCII 字符无法被正确的识别。当py 访问其他文件,将数据写入文件时也需要注意字符编码。
故障2:Python2 默认编码是ASCII 码
>>> example = u'你好'
>>> str(example)
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
str(example)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1:
ordinal not in range(128)
>>> example = u'你好'
>>> open('temp.txt','w').write(example)
Traceback (most recent call last):
File "<pyshell#3>", line 1, in <module>
open('temp.txt','w').write(example)
UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-1:
ordinal not in range(128)当用u’字符串’ 的形式申明这个字符串变量时,也就指明了该字符串是使用unicode 字符编码。当如果要将unicode 字符串转换为str 字符串(python2 认为unicode 字符串和str 字符串是不同的)或者写入文件时,python 将默认使用ASCII 码保存数据,而ASCII 码无法识别大于128 的字符,于是报了上面的错误。
类似这样的错误还有:
>>> unicode('abcdef' + chr(255))
Traceback (most recent call last):
...
UnicodeDecodeError: 'ascii' codec can't decode byte 0xff in position 6:
ordinal not in range(128)2.3 终端编码
上linux 操作系统课程的时候,我们被教导到:一切都是文件,终端作为一种设备也是文件,当需要输出内容到终端时,实际上也是按照终端对应的字符编码显示相应的内容。
故障3:如果你在windows 终端cmd.exe 运行下面代码(需要安装requests 包)。
import os,sys
import requests
ss = requests.Session()
res = ss.get("http://www.hust.edu.cn/")
con = res.content
print con这段代码是获取http://www.hust.edu.cn/ 页面的内容,并在终端显示,(如下图)这里出现了乱码。
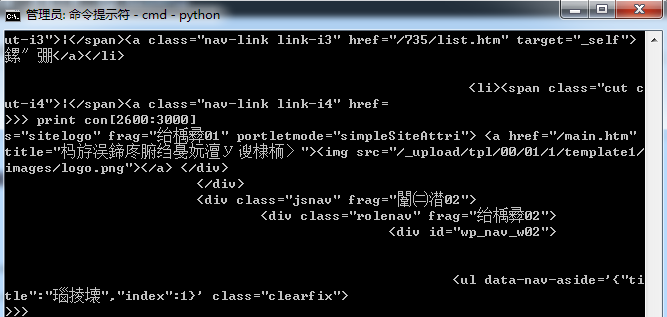
但如果你进一步将con 中内容写入到文件或者在linux 下运行这段代码,可能则没有乱码的问题。问题出在哪里呢?原因是因为页面内容是UTF-8 编码(可以在页面源码<meta charset=”utf-8“>中看到 ),而windows 命令提示符cmd 中却使用的是mbcs 字符编码。可以通过下面的命令查看该终端的字符编码
print sys.getfilesystemencoding()熟悉Linux 的应该知道,终端也是要设置语言格式的,否则在此终端上显示的文件,文件名以及输出到终端的内容会存在乱码。可以通过下面命令设置linux 终端字符编码为UTF-8:
export LC_ALL=en_US.UTF-8
export LANG=en_US.UTF-8
export LANGUAGE=en_US.UTF-82.4 str 和unicode
计算机保存的数据,以及从文件中读取的数据都可以理解为str 字符串,str 字符串是需要字符编码才能够被计算机所理解,而unicode 字符串采用统一的字符编码方法。为节省空间等原因计算机并不会直接存储unicode 类型。但在Python2 处理字符数据时,建议全部转化为unicode。
但如果不知道str 字符串编码类型,按照Python2 默认的ASCII 码转换出现大于128 的字节的错误怎么办(UnicodeEncodeError: 'ascii' codec can't encode characters)?
有两种方法:一是用特定的数值(magic number)替代错误的字节;二是干脆忽略错误字节
>>> unicode('\x80abc', errors='replace')
u'\ufffdabc'
>>> unicode('\x80abc', errors='ignore')
u'abc'
同样地,encode() 和decode() 也可以这样使用。
str 字符串和unicode 字符串进行比较,或者合并两个字符串时,首先将它们转换为unicode 格式,再计算它们的值。比如合并str 字符串’你’ 和unicode 字符串u’你’,因为’你’ 按照默认的ASCII 码发现无法解码’你’,于是报错了~~~
>>> '你'+u'你' Traceback (most recent call last): File "<pyshell#0>", line 1, in <module> '你'+u'你' UnicodeDecodeError: 'ascii' codec can't decode byte 0xc4 in position 0: ordinal not in range(128)
看下面的例子比较str 和unicode 字符串,python2 按照默认的ASCII 码解码为unicode 过程中发现无法识别的字节,然后就返回不相等(False),并抛出一个异常。
>>> if '你' == u'你':
... print True
>>>
>>> '你' == u'你'
__main__:1: UnicodeWarning: Unicode equal comparison failed to convert both argu
ments to Unicode - interpreting them as being unequal
False
正确比较方法应该是:
>>>'你'.decode('gb2312') == u'你':
True
>>> 如果你在百度或者Google 上搜索解决str 字符串在转码为unicode 时不知道字符编码类型的“问题”时,大部分时候你会看到大家提出在py 文件上加上两句:
reload(sys)
sys.setdefaultencoding('utf-8')这样py 文件中str 字符串默认以UTF-8 编码。但一位有经验的Python 程序员会告诉你尽量不要这样做,因为这样在对于不是UTF-8 编码的字符时,还是会出现乱码,下节再谈这点。
2.5 _*_encoding:utf-8_*_ 和 reload(sys) sys.setdefaultencoding(‘utf-8’)
有了上面一节的基础,我们大概知道了
#_*_encoding:utf-8_*_放在py 源代码之前申明,表示py 源文件是UTF-8 编码(即文件中所有的字符都是UTF-8 编码)。这样的好处是如果py 源文件中存在非ASCII 码的字符(你写代码时所输入的UTF-8 字符),python 程序也能够正常的识别为你所输入的字符,而不是按默认为ASCII 码(这样在运行时会抛出无法识别为ASCII 码的错误)。
这种申明文件编码类型是我们推荐的,而下面
reload(sys)
sys.setdefaultencoding('utf-8')这两句话申明py 文件中所有str 都是UTF-8 编码的,而这种强制定义所有str 字符串为UTF-8 编码是我们不推荐的。比如会遇到下面的问题,在一个测试文件test.py 中有内容:
#_*_encoding:utf-8_*_
import os
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
sym1 =u'♀'+'你'
sym2 = '你'.decode('utf-8').encode('gb2312')
ff = open('temp.txt','w')
ff.write(sym1)
ff.write(sym2)
ff.close()
然后用notepad++打开temp.txt 文件,看到了什么内容呢?
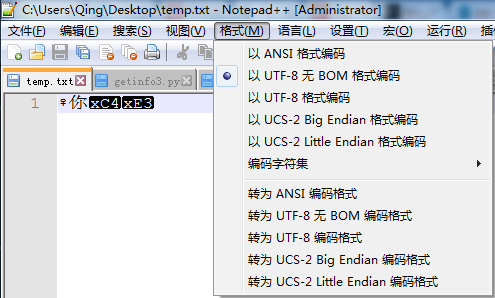
不难看出,’♀’ 和’ 你’ 显示都没有问题,但后一个’你’ 就因为使用的是GB2312 编码,写入文件后,前两个字符都是UTF-8 编码,后一个字符GB2312 编码,用UTF-8 格式打开时,最后一个编码肯定就显示不正常了。
当然,上面只是一个例子,很多时候你不会在程序中写出这么buggy 的代码,但是很多时候用python 处理一些非UTF-8 编码的文件或者数据时,就会因为你强制申明str 为UTF-8 编码导致很多问题,比如读取非UTF-8 编码的Oracle 的数据库,修改、添加非UTF-8 编码的文件时,就会产生很多字符编码混乱。因此也有人建议python2 程序员在处理str 时能够显示地使用特定合适的字符编码,而不是默认地使用UTF-8。
Python3 只有unicode 字符串,而没有str 字符串,上面所遇到的字符编码的坑不再有了。
所以—— Bravo~ 学Python3 去吧,骚年!